The upcoming
0.9.4 release of Reticulum will include a series of significant improvements to system resource utilization. Work has been focused on the core I/O handling and internal in-memory data structures. This has resulted in substantial reductions in both memory consumption, thread counts and CPU utilization, especially noticeable on nodes with many interfaces or connected clients.
Lighter Memory FootprintThe in-memory table structures have been optimized
significantly, and disk caching added for data that doesn't need to stay loaded in resident memory. Memory cleanup, path table management and table entry purging has also been overhauled and optimized.
The net result is a
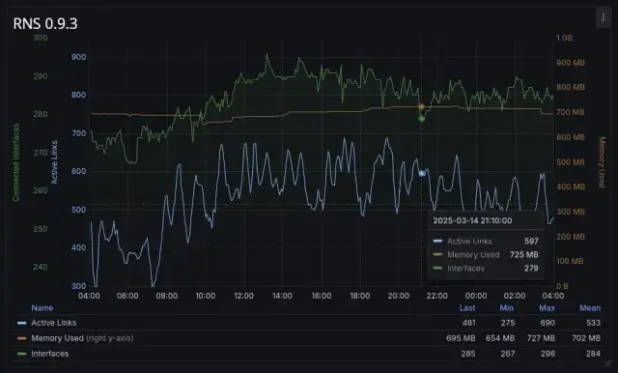
reduction in resident memory load of approximately 66%. As an example, one testnet node with 270 interfaces and around 800 concurrently active links incurred a memory load of 710 MB on
rnsd version
0.9.3.
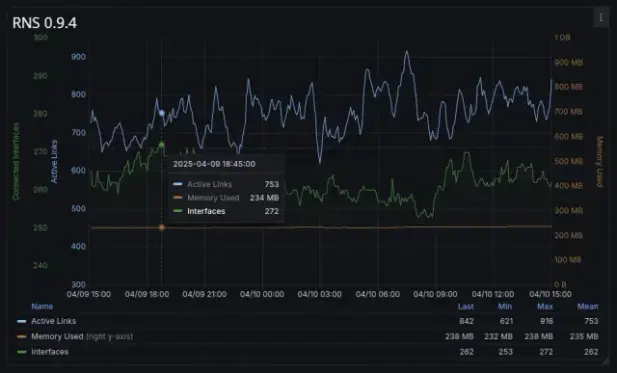
With the new optimizations in
0.9.4, memory load stabilizes at a much lighter
230 MB under similar conditions.
These improvements are of course going to be most noticeable on well-connected transport nodes, but even for small or singular application-launched instances, the improvements are important, and contribute to the goal of running even complex RNS applications on very limited hardware.
Faster I/O BackendA new backend for handling interface I/O, and shipping packets off to the RNS transport core, has also been added in this upcoming release. It uses kernel-event based I/O polling, instead of threads for reading and writing the underlying hardware (or virtual) devices. This approach is
much faster, and of course decreases processing time wasted in multi-threading context switches significantly.
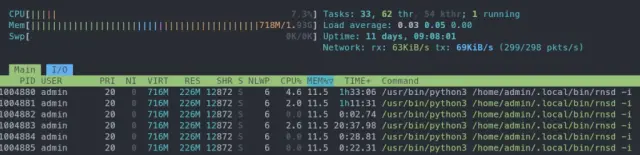
On RNS
0.9.3, the example node from before utilized around 275 threads, but on version
0.9.4, everything is handled by a mere
6 threads, grand total. That includes
all the threads of RNS, like those needed for running memory maintenance, managing storage and caching, and other backend handling.
Additionally, the new I/O backend uses abstract domain sockets for communication between different RNS applications on the same system, offering a slight, but still welcome performance improvement. More importantly, though, using domain sockets for intra-RNS instance communications makes it much easier to handle several different RNS instances running on the same system, as these can now simply be given human-readable namespaces, making config file management and complex setups a lot more manageable.
To run several isolated RNS instances on the same system, simply set the
instance_name parameter in your RNS config files. You can verify that your instance is indeed running under the correct namespace (here the default
system namespace) by using the
rnstatus command, which should give you output such as the following:
Shared Instance[rns/system]
Status : Up
Serving : 3 programs
Rate : 1.00 Gbps
Traffic : ↑8.61 GB 798.45 Kbps
↓11.51 GB 859.64 Kbps
In this initial release, the new I/O backend is available on Linux and Android. The plan is to extend it to Windows and macOS in future releases, but since these operating systems have different ways of interacting with kernel event queues, it makes sense to stage the deployment a bit, and make sure that everything is working correctly before adding support for these as well.
Lower CPU LoadThe improvements to memory structure, increased I/O efficiency and decreased thread counts all contribute to lowering the CPU load required to run Reticulum. Especially the much decreased need for context switching makes a positive difference here, and this is very noticeable on systems that handle very large numbers of interfaces or connected clients.
The testnet node referred to in this post is a small single-core VM, that handles between 250 to 320 interfaces, and between 700 to 1,000 active links at any given time. Even on such a small machine, CPU usage rarely spikes above 15%, and long-time load average is essentially always at
0.01.
While there is still many more options to work on, for even better performance and lower resource utilization, this work is a big step forwards in terms of immediately useful scalability, and the ability to deploy even large and complex Reticulum-based systems and applications on very modest hardware, such as low-power SBCs and embedded devices.
#
reticulum #
performance #
networking #
meshnetworks




 (he / they)
(he / they) 

















 Node
Node


